Having the same content in multiple places on your website or different websites can be a big problem when getting found online. This is called duplicate content, and it can confuse search engines like Google. When search engines find the same content in multiple spots, they have difficulty deciding the most important one. As a result, they might not show your website as high in the search results, or they might not show it at all. Why is having duplicate content an issue for SEO?
This is why duplicate content is unsuitable for making your website easy to find. In this article, we’ll talk about why it’s essential to have unique content, how having the same content in multiple places can cause issues, and what you can do to fix it. This will help your website do better on search engines and make it easier for people to find you online.
What is Duplicate Content?

Search engine optimization can be severely hampered by having the same content on several pages of your website or other websites. This is known as duplicate content, which may need clarification for search engines like Google. When search engines come across identical content in various locations, they need help to determine the most relevant one. Consequently, your website may not rank highly in search results or may not appear at all.
What are the risks of duplicate content?
Duplicate content can harm your website’s search engine rankings, reduce visibility, waste crawl budget, confuse users, dilute authority, and potentially lead to legal issues. To mitigate these risks, regularly audit your content and take steps to address any duplication, such as using canonical tags, redirects, and creating unique, valuable content.
What makes duplicate content a problem for search engine optimization?
That’s why having duplicate content can hinder your website’s searchability. Let’s discuss the importance of original content, problems arising from duplicate content, and how to address this issue. Implementing these strategies will improve your website’s search engine ranking and become more visible to online users.
Types of Duplicate Content: Internal and External Threats to SEO
Internal Duplicate Content:
Internal duplicate content refers to content that appears more than once within the same domain. Causes of internal duplicate content include:
- URL Variations: Different URLs lead to the same content, often due to URL parameters for tracking or session IDs.
- WWW vs. Non-WWW: Content accessible through www and non-www URL versions without proper redirection.
- HTTP vs HTTPS: Similar to the WWW issue, content is accessible via HTTP and HTTPS protocols without redirecting to one preferred version.
- Content Replication: Identical content published on multiple pages within a site, such as product descriptions or blog posts.
External Duplicate Content:
External duplicate content exists when identical or substantially similar content is found across different domains. This can happen due to:
- Content Syndication: When original content is intentionally shared on other websites without signaling the source to search engines.
- Content Scraping: When content is copied from one website and published on another without permission.
- Cross-Domain Duplicates: When the same or similar content is published across different websites owned by the same entity without proper canonicalization.
Why Google Dislikes Duplicate Content and Its Impact on SEO
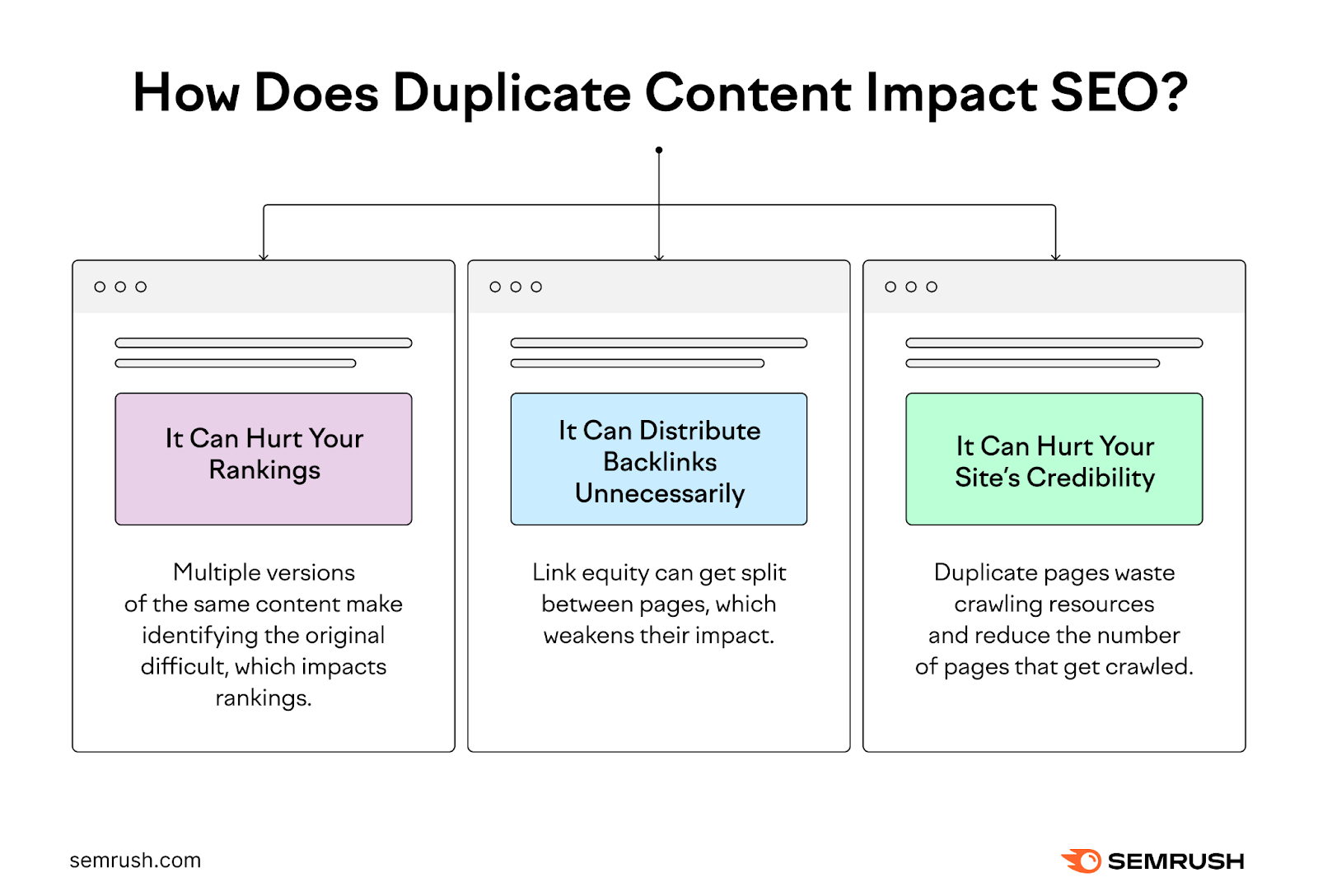
Duplicate content can significantly hinder your website’s SEO performance in several ways:
Search Engine Confusion:
When search engines encounter duplicate content, they need help determining which version is the most relevant and valuable to display in search results. This can lead to:
Reduced visibility:
Search engines might de-index duplicate pages, essentially removing them from search results altogether.
Ranking inconsistency:
Even if both versions remain indexed, search engines need to know which one to prioritize for specific keywords, resulting in unpredictable and inconsistent rankings.
Diluted Link Equity:
Backlinks act like votes of confidence from other websites, telling search engines that your content is trustworthy and valuable. However, when duplicate content exists, the link equity spreads thinly across all versions, weakening the overall SEO power of each page.
Wasted Crawl Budget:
Search engines have limited resources and allocate a specific amount of time and energy to crawl and index websites. When they encounter duplicate content, they might spend their crawl budget on indexing these redundant pages instead of discovering and indexing your unique and valuable content. This can slow the indexing process and hinder your website’s overall discoverability.
Poor User Experience:
Duplicate content creates a confusing and frustrating experience for users. Imagine landing on a page that seems identical to one you’ve already visited. It feels repetitive and diminishes the value of your website, potentially leading to higher bounce rates and lower user engagement, both of which are negative signals for search engines.
Best Practices to Avoid Duplicate Content

Avoiding duplicate content is crucial for maintaining the health and effectiveness of your SEO strategy. Here are some best practices to help you manage and prevent duplicate content issues:
Create Unique Content:
Strive to create unique content for each page on your website. If similar products or topics require similar descriptions, take the time to differentiate each piece to add value and uniqueness. If you syndicate your content to other sites, ensure that those sites link back to your original article with a canonical link. This signals to search engines where the original content resides.
Use Canonical Tags:
Implement canonical tags to indicate to search engines which version of a content piece is the “master” or preferred one. This helps consolidate link equity and ranking power to the specified URL, even if other versions exist.
Implement 301 Redirects:
If you have multiple pages with duplicate content, use 301 redirects to guide users and search engines to the primary page. This helps with SEO and improves the user experience by reducing confusion.
Manage URL Parameters:
Use the Google Search Console to specify how search engines should handle URL parameters that might create duplicate content. This can include parameters used for tracking, sorting, or filtering content on your site.
Conclusion:
In summary, duplicate content significantly harms SEO by confusing search engines, diluting link equity, risking penalties, and undermining user experience. Addressing it through best practices like canonical tags, implementing 301 redirects, and creating unique content is crucial for maintaining a solid online presence. Ultimately, avoiding duplicate content enhances SEO and improves site credibility and user satisfaction, laying the foundation for long-term digital success.
Leave a Reply